
Revolutionizing Document Data Extraction: How LLMs Outshine Traditional Tools
From Legacy Methods to AI-Powered Efficiency: Unlocking the Potential of Large Language Models in Document Processing


PDF data extraction has been a challenging task for years, especially when dealing with complex layouts and unstructured data. I’ve had a couple of scenarios where I needed to extract information from PDFs and looked into various tools and techniques to do that.
Well, before the advent of LLMs, tools like PDFBox and Amazon Textract were commonly used. Out of which a ton of companies where built, but to be honest, most where just AWS Textract wrappers with a massive price tag and some more features on top to justify the 100x in pricing 😅
.. nothing new in the software world really 🤷♂️ that’s until llm came into the picture, but more on that 👇
Traditional Methods #Legacy
Pros: Open-source, allows for text extraction and basic document manipulation.
Cons: Not thread-safe, requires manual handling of permissions and passwords for encrypted documents, and can struggle with complex layouts
Use Case: Suitable for simple text extraction tasks, especially when cost is a concern.
Pros: Powerful for extracting text, forms, and tables from PDFs; integrates well with AWS services.
Cons: Limited support for custom field extraction, no on-premise deployment, and lacks fraud detection capabilities
Use Case: Ideal for organizations already invested in the AWS ecosystem and needing structured data extraction.
These are some common pros and cons, but from my experience there are quite a few more.. 👇
AWS Textract is veeery cheap, no other tool can compare honestly
AWS Textract doesn’t support many languages. I once tried to make an expense tracker app, where you can take a picture of your receipt and all data would be saved into your app automatically. Well, safe to say that data from Bulgarian receipts was transcribed into Egyptian in the database lol 😂
That' said, there a ton of Textract wrappers that, for example specialize in handling more languages or give better data in a specific language, and that is their selling point.
PDFBox is just 💩 - it is open source and is considered legacy by many. I’ve used it a lot in previous jobs. Don’t even try using it TBH, you will just waste time and effort to get 3-4 fields out of a PDF


The Advent of Large Language Models (LLMs)
LLMs have revolutionized document data extraction by offering higher accuracy and efficiency, especially in handling complex documents.. and that’s an understatement.
How did I come to this realization? Well, it wasn’t from some X thread or smth like that..
One day, I was looking into how can we extract data more efficiently, as at Tide we had to get data from invoice PDFs. I was sitting with a friend that day and an idea popped into my head, why don’t I just pass the PDF to an LLM API, tell it to give me the data in JSON response and see what happens 👀
Boom, the LLM, I think we tried it with Deepseek and OpenAI, gave me all of the data from the PDFs, with 99.99% accuracy. And that’s on 10 or more PDFs I tested it with on the spot. 🤯
It did amazingly well even with the Bulgarian receipts I mentioned earlier.. and with every other document 😅

Advantages of LLMs
Accuracy and Efficiency: LLMs can accurately extract structured data from complex documents, reducing a lot of manual intervention and errors.
Flexibility: They can handle diverse document types, including scientific papers, financial reports with multi-column tables, reports and so many more.
Ease of Use - it’s as simple as using a LLM API, pushing the Document/File, tell it to return the response as JSON & voilá - you have it all 🔥
Disadvantages
It may get expensive 😅. That’s really the only CON I see.. If you were to self-host, it would be an expensive initial cost and very cheap in future. If you were to use an existing LLM, the bill, compared to smth like AWS Textract for sure spikes.
Do your own research and validate if including AI into your data extraction solution fits the business needs and doesn’t brake the bank 🏦

LangChain with Amazon Textract
Here, we can combine the power of LLMs with the existing tools. Combining the strengths of Amazon Textract with the flexibility of LLMs, allows us to have structured data extraction and integration with other AI services!
I can tell you, there are A LOT of businesses that need this powerful tool (extracting data from files in structured way) 🤑
It’s amazing for companies, who already use AWS and are open to integrate LLMs into their business.
Worth to say - LangChain is open-source, but LLM calls aren’t free 😅
An Example Of How ChatGPT Extracts Data In JSON Format
Let's ask GPT 4o to extract the data from a set invoice in JSON format.
Here is an example invoice:
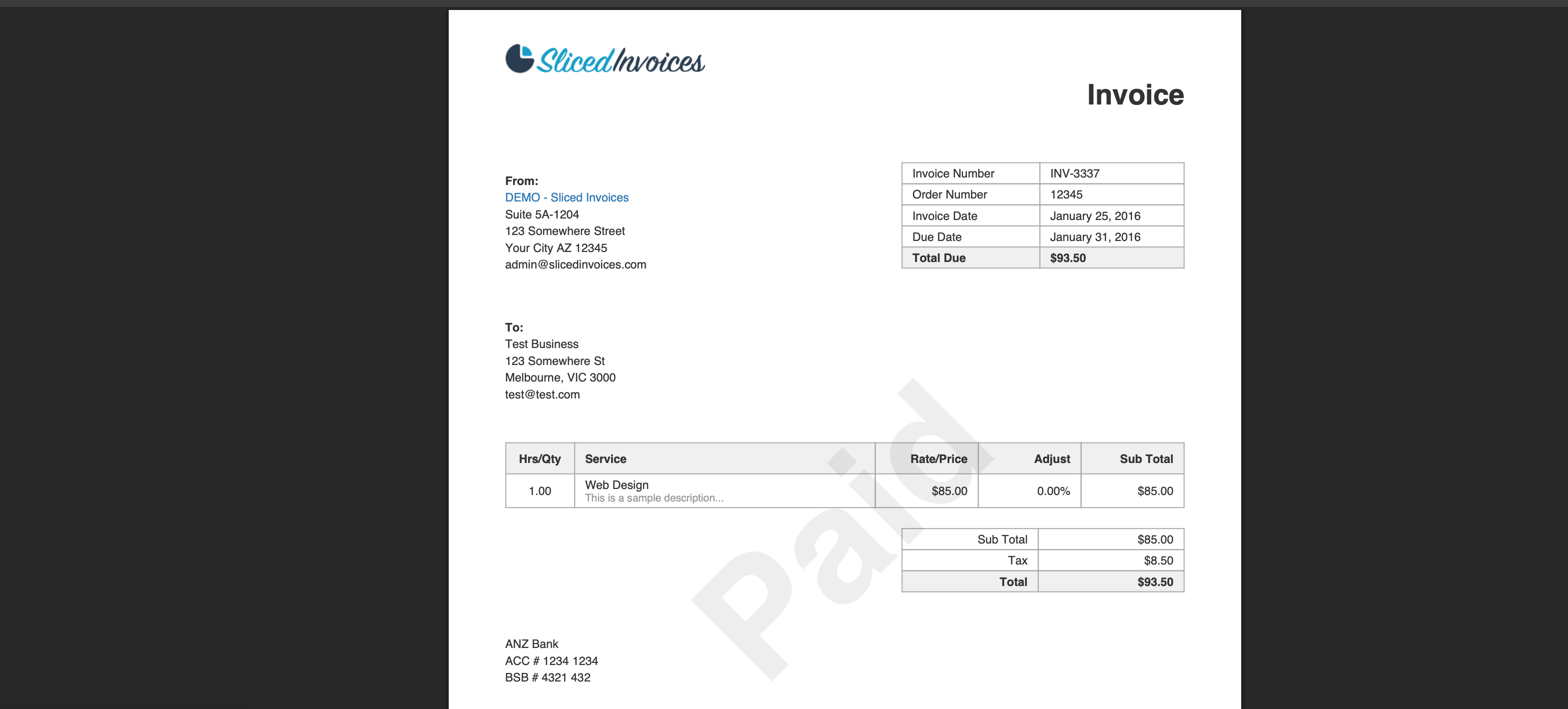
now, lets ask the LLM to give us an extraction in JSON format:

and what we get:

we get everything.. insane 🤯
Real-World Examples of PDF Data Extraction
Let’s go through some real world usages of this. They are already happening, so you can feel the FOMO already 😛
Healthcare Data Extraction
As per this article, AI and Intelligent Document Processing (IDP) have significantly improved data extraction from diverse documents such as medical bills, patient forms, and lab reports. This large hospital network automated claims processing by using an IDP solution with AI and ML algorithms, which extracted data from medical bills and other documents, validated the information, and submitted claims electronically.
Financial Data Extraction
This study leveraged LLMs to extract financial data from PDF-formatted governmental and corporate reports. The framework achieved an average accuracy rate of 99.5% in extracting key financial indicators, demonstrating the potential of LLMs in financial data extraction
Legal Document Data Extraction
Tools such as Kira Systems use ML to extract data from contracts and other legal documents, helping legal teams automate document review and identify vital clauses without manual searching. So all my friends that study law will already see the benefits of having such tools in their toolkit 😜
Scientific Research Data Extraction
In scientific research, tools like Nougat and Mathpix are used to accurately extract formulas from PDFs. LLMs can then be applied to summarize breakthroughs and analyze complex scientific content, making it easier to understand and utilize research findings
Patient Insurance Data Extraction
Very cool blog-post revealed a recent experiment using the Llama-3.1–70B model to extract patient insurance data from PDF files. The workflow involved extracting text from PDFs using PyPDF2 and then processing it with the LLM to extract key information, which was stored in MongoDB for future use! 🚀
Some Advice, Tips and Tricks for Effective PDF Data Extraction with LLMs
If you wanna learn how to cook, here me out here 🫡
Document Preparation: Ensure documents are well-formatted and free of errors to maximize extraction accuracy.
Model Selection: Choose LLMs tailored to your specific document types (e.g., scientific vs. financial).
Post-Processing: Implement additional checks for data consistency and accuracy after extraction.
Integration: Consider integrating LLMs with existing workflows or tools for seamless data processing. Store extracted data in databases like MongoDB for easy access and analysis.
Visual Grounding: Use technologies like Agentic Document Extraction for visual grounding, which links extracted data to its exact location in the document, enhancing verifiability
Also, there are a lot of companies that are building on top of LLMs to provide document extraction services, so make sure you look into them as, from experience, they are pretty damn good 🔥
Conclusion
💡 Since AWS have AWS Bedrock, I think they will do some ‘magic’, combining AWS Textract with the Anthropic’s models to improve their existing services. Even tho LangChain already do something very similar.
That said, the shift from traditional PDF extraction tools to LLMs marks a significant improvement in efficiency and accuracy.
⚖️ By understanding the strengths and limitations of each approach, businesses can optimize their document processing workflows and leverage the power of AI for better decision-making.
Was this blog-post interesting to you? Did you get some value?
Hope so 🔥 as I did learn a lot while researching and experimenting 🫡
Let’s connect on LinkedIn 🤝 https://www.linkedin.com/in/kbor/
Great article! The Visual Document Extraction idea you’ve mentioned is super helpful, I have a use case for it. Do you know of any open sourced or self-hosted alternatives to the service you are mentioning right there?