


Consistent Hashing: The Key to Scalable Distributed Systems
Learn how to implement consistent hashing and virtual nodes to optimize your distributed systems.

as I am back to the system design prep and studying, one of the more exciting and interesting topics I came back to was consistent hashing.
this technique has done wonders to many systems and diving deeper into how it works and the real-world implications of it has been very exciting!
.. so let me tell you what I learned and hopefully give you a nice refresher or intro to the topic 💪

⚠️ quick note: i mention servers, instances and nodes pretty freely in the article, so bear with me - all of them refer to the same thing 😅
The Initial Problem You’ll Face
Imagine you're managing a distributed system with multiple servers handling user requests. Initially, you distribute traffic using a simple hash function:
server_index = hash(user_id) % number_of_servers
.. where the server_index is a unique identifier of each available server in your system.
well, this works well until you need to scale. More specifically, what happens when you start adding or removing servers? 👉 the number_of_servers changes.
This leads to a complete reshuffling of user-to-server mappings:
i.e. adding 1 server to a 10-node cluster reshuffles 90% of keys
for more visual representation of this, check HelloInterview’s graphics here!
all of a sudden, user sessions are lost, caches are cold, and your system is in chaos 🧯
The Solution: Consistent Hashing Enters The Chat 😎
Consistent hashing solves the above problem by mapping servers and keys to a virtual ring (also called `hash ring`), using a uniform hash function. This provides the following benefits:
adding / removing servers only affects K/N keys (where K - keys, N - nodes)
this technique is used by the biggest companies in the world to scale their systems - Discord, Meta, Amazon..
but to better understand this, let’s do a deep-dive on the technique 👇
Initializing the Hash Ring
we make ring/circle and set a fixed set of points, for example 12.
then evenly distribute the database instances on that ring - in our case 4 DBs.

How Do We Store Data On A Hash Ring??
but when a new piece of data comes on, how do we know to which DB we should assign it to? where should we store it?
the flows goes like this: we hash the user_id → we find where the generate hash number sits on the ring → based on that, we move clockwise until we find a DB instance → once we find the instance, we place the hashed user_id in that DB instance!

and to have a better representation of how it would look like when we have multiple keys (pieces of data) being assigned to their respective DB instances:

Adding / Removing Instances From The Hash Ring
very cool. we can add data to some DBs. but how does this differ from the modulo approach, which is way simpler to implement?
💪 here comes the power of consistent hashing - adding and removing instances (in our case DB instances)
a tl;dr and most important thing to remember here is that with consistent hashing only a fraction of keys needs to be reassigned. whereas with other approaches like modulo, all keys must be reassigned -i.e. we achieve minimal disruption
this helps us achieve better scalability & stability of the system!
Adding Nodes

as you can see on the ugly drawing of mine - when we add a DB5 Instance, part of the keys which were stored or distributed to DB1, now need to be redistributed to the new DB5. But, this is good as only a fraction of the keys need to be moved!
key takeaways:
only a fraction of the keys are moved, reducing overhead associated with data redistribution
new servers can be added seamlessly without significant impact on the system’s performance!
Removing Nodes
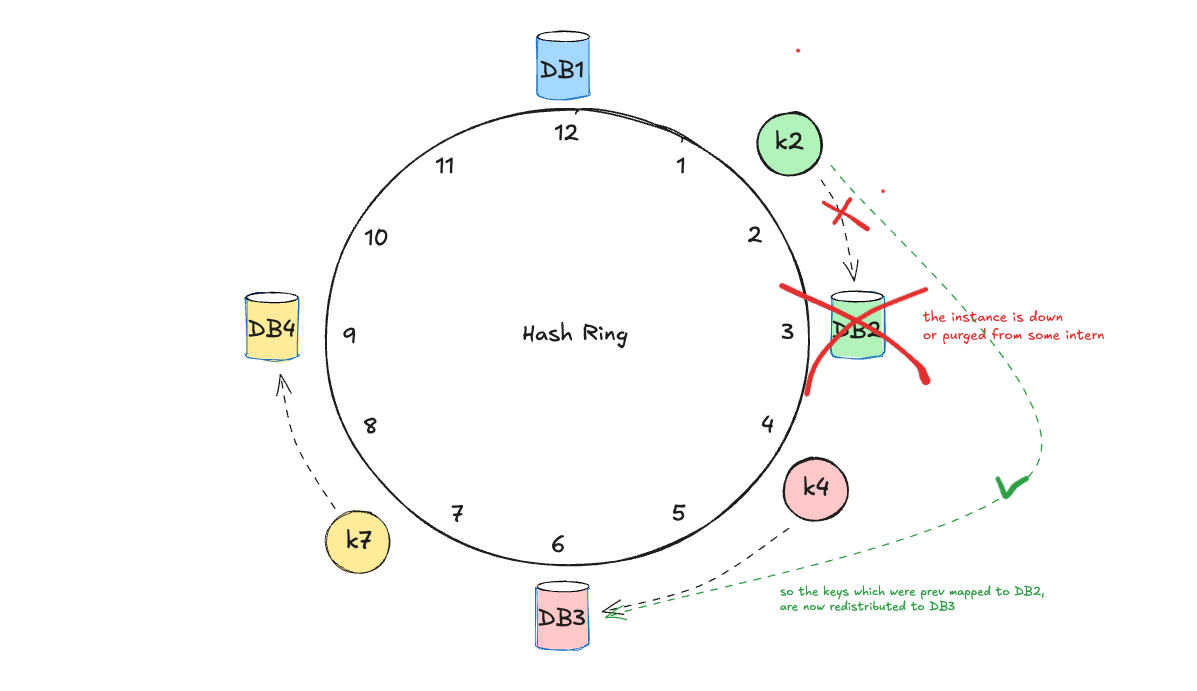
with this, we achieve the following benefits:
better fault tolerance - the system continues to operate smoothly even when servers are removed
efficient recovery - as only a subset of keys need to be reassigned, facilitating quick recovery
But What About Uneven Load Distribution?
while consistent hashing minimizes data movement during node changes, it will still lead to uneven load distribution if servers are not evenly spaced on the hash ring.
just take the above removal of DB2 instance as an example. Now DB3 instance has potentially double (2X) the load the other instances. or even worst.
because of that, we would want to spread the load coming from the removal of DB2 evenly so that DB3 isn’t taking all of the heat 🔥
💪 … to do so, let’s add some system design steroids into our stack: virtual nodes
Virtual Nodes (vnodes)
the solution is to hash different variations of the DB instance names (so DB1, DB3, DB4..) and place the results as different points on our hash ring - these will be called vnodes!

more formally:
each physical server is assigned multiple positions (vnodes) on the hash ring, which ensures more uniform distribution of keys across all servers
❗️ so, to recap and tl;dr on what advantages we get with virtual nodes, here is a key-value map 😉:
{ load balancing, “by spreading virtual nodes evenly, we prevent any single server from becoming a hotspot” }
{ scalability, “adding or removing servers affects only a fraction of the data, minimizing redistribution” }
{ fault tolerance, “if a server fails, its virtual nodes' responsibilities are smoothly taken over by neighboring nodes” }
to put it into perspective.. in a 100-node cluster, 1 node failure affects 1% of keys. 🔥
there are some specifics around vnodes, which we won’t go through in this article. that said, I’ll make sure to cover them in future LinkedIn posts or blog-articles here!
Theory Done. But Is Consistent Hashing Used in The Real-World?
oh yes.. a lot.
here is a small and powerful list of software tools, applications and services, which leverage consistent hashing to achieve the impressive metrics & scale they did:
Akamai CDN (used by Meta) uses consistent hashing for content routing. It has 325k servers with <1ms lookup latency!! 🤯 Read more here
Cassandra (used by all of software 😆) uses CH for data partitioning. You can get 10-100 vnodes per physical node! → Article going more in-depth here !
BitTorrent used it for peer discovery and achieved 98% reduction in reshuffling during churn!
Google Cloud uses it for their load balancing - effectively hitting zero-downtime scaling for GMail’s backend!
Amazon DynamoDB:
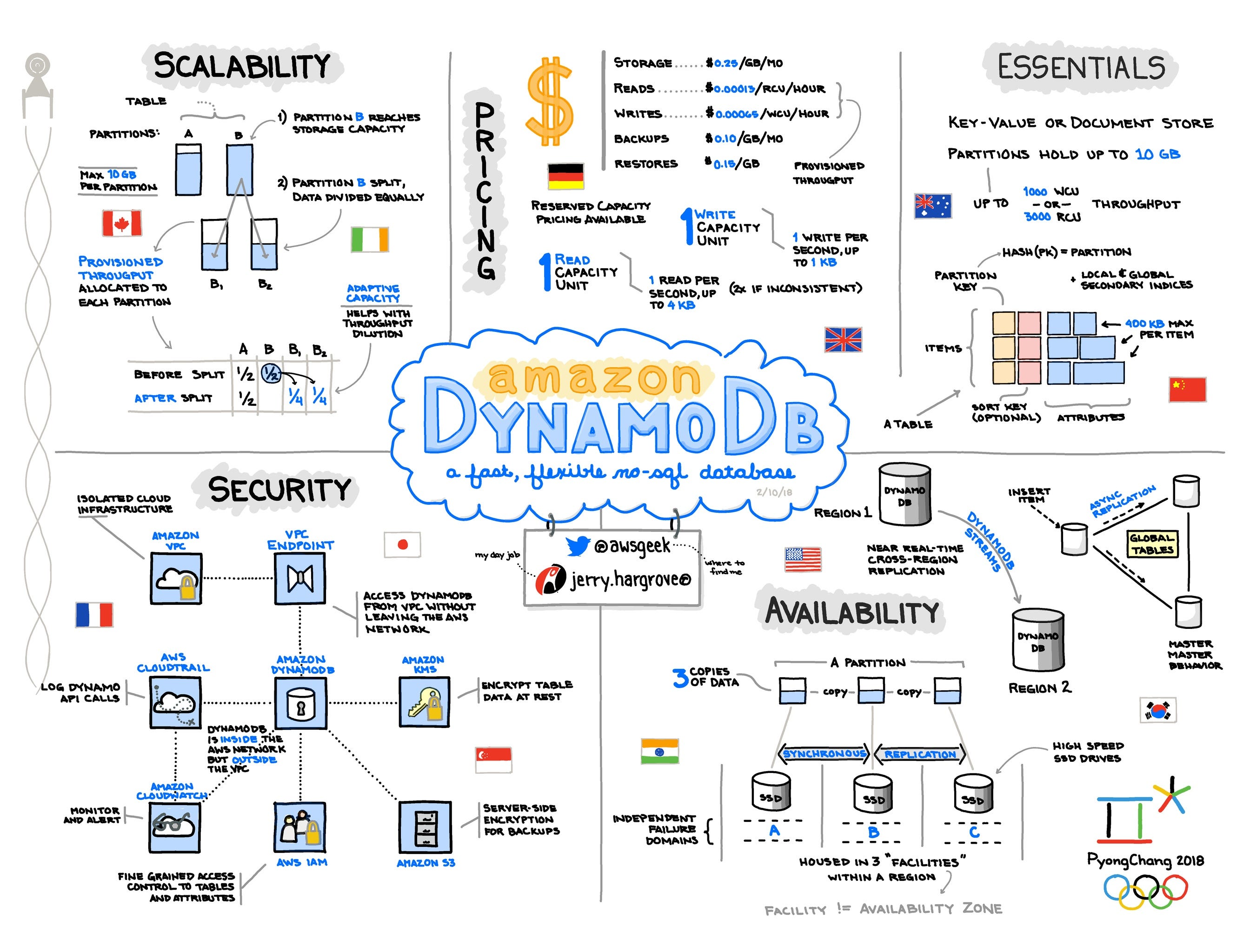
{kind=link}
of course, there are many many more examples that showcase the importance and effectiveness of this technique!
that being said, make sure to share the knowledge with peers and colleagues.
i think this blog-post might serve as a good intro or refresher for people interested in the topic or preparing for system design interviews!
finally, if you want a deeper-dive, I heard that the AWS DynamoDB’s whitepaper is a goldmine for learning about key-value stores and consistent hashing! I’d definitely give it a read in future!
✔️ follow me on LinkedIn @ Konstantin Borimechkov for daily system design and software engineering bytes!
that said, have a productive week! 🚀