
Amazon DynamoDB Deep Dive: Key Components, Use Cases, and Features
Nail your next System Design Interview with Amazon's DynamoDB - Scaling to over 140+ requests/second! This may be THE All-In-One Database you need in your Interviews.. or not?

got inspired by HelloInterview’s video on DynamoDB and one of my recent experiences in using Dynamo in an interview..
‘you just need to learn PostgreSQL and DynamoDB. that gets you covered in terms of the DB choice on the interview!‘ ✔️' - got this from HelloInterview
so.. i decided to provide a UI/UX friendly explanation and a little deep-dive on the technology. And I promise, this won’t be your typical “DynamoDB = key-value, scales, done” cheat-sheet.. 🫡
what to expect? - deep-dives on the fundamental features, graphics, real-world examples, interview cheat-sheet and more.. get ready for the next sys design 💪
quick intro
what it is – fully-managed, Serverless* NoSQL store that can burst from 0 QPS to 146 million requests / sec (Amazon Prime Day 2024) while holding trillions of records
why you care in interviews – you get Horizontal Sharding, Multi-AZ HA (Availability Zones High Availability), Global Replication, Streams, TTL, and even ACID transactions without touching a server (from around 2018, DynamoDB provides stronger guarantees via transactions)
serverless in AWS-speak = you pay RCU/WCU (Read/Write Capacity Units), not per number of EC2 instances (on-demand pay)
Partitioning - ‘sharding without the drama’
what’s partitioning in the world of dynamo?
DynamoDB hashes the partition key → routes the call to one physical partition (that’s the physical location of the Database server/node)
each partition can do ≈ 3 k reads / 1 k writes per sec!
if more more traffic comes, DynamoDB auto-splits behind the curtain (this is is very close to consistent hashing, just not showcased in the ‘keys moving in clockwise fashion’ kind of way)
let’s learn through a real-world (prevented) incident 🗺️
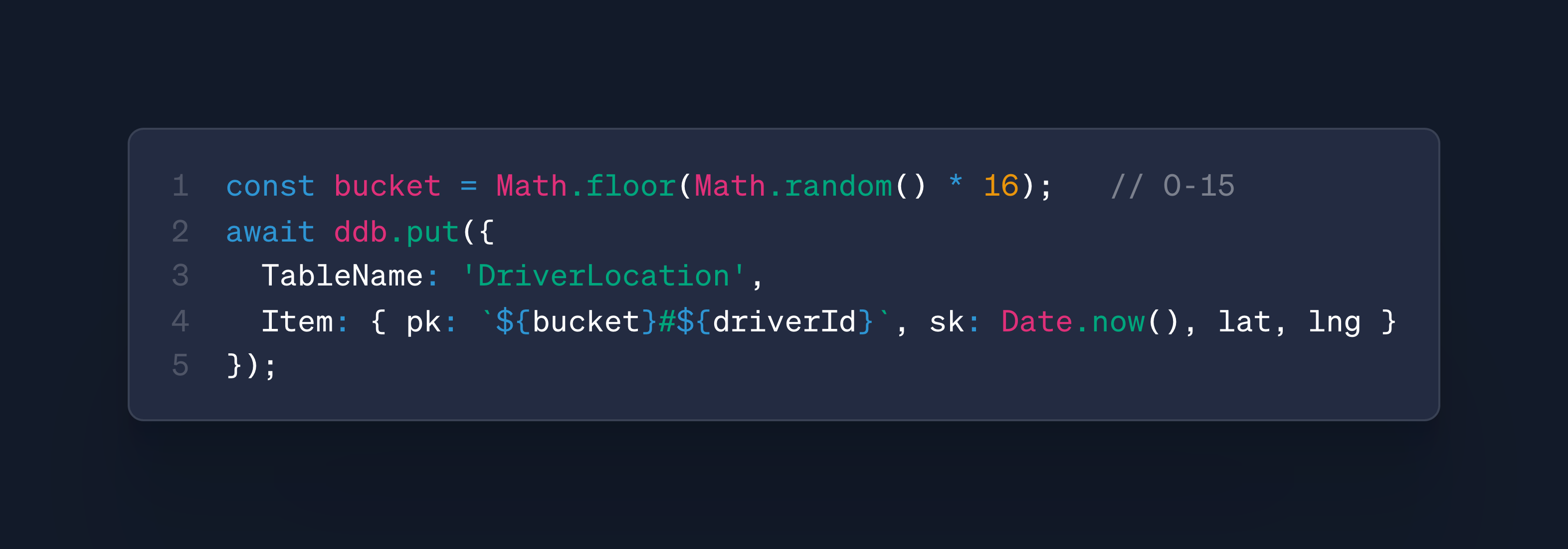
Lyft’s ride-tracking GPS table wrote the same driver_id over and over..
a hot key started throttling (the drive_id being the hot key) → meaning rides stalled 🥶
the quick solution? → engineers prefixed the key with a random bucket (03#driver_123), which effectively spread the writes across a wider range of keys.
Throughput issues vanished. Check this for more cases!
what about a mini code snippet of the above solution? (write sharding) 👨💻
ship-it checklist
✔️ PK (Partition Key) has > 10× more unique values than partitions
✔️ monitor CloudWatch Most-throttled Keys
✔️ if one key is ultra-hot ⇒ add random/bucket prefix (i.e. what Lyft did)
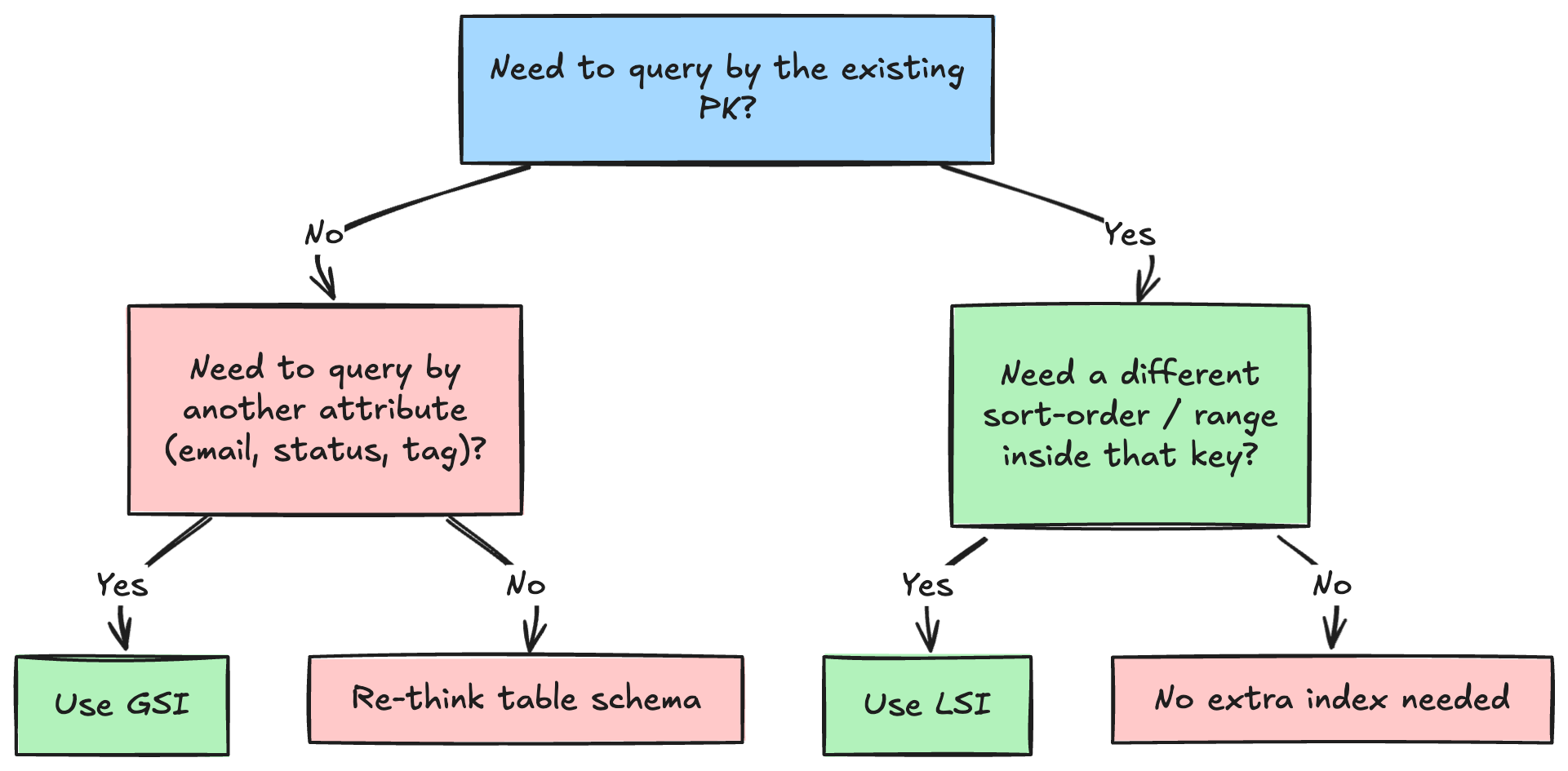
Indexing in DynamoDB
in DynamoDB, we have:
Partition Key (PK):
that’s basically the core index. partition key separates the data into partitions.
for example `userId` or `countryOfOrigin`
Sort Key (SK):
the order of items inside the partition
the only way to make range queries on our data are SKs
Local Secondary Index (LSI):
as the name suggests, this index is local to the partition. That is basically another (new) sort key
to remember more easily, think of it as: another way to filter/sort within each node
must be created when a table is created.
Global Secondary Index (GSI)
that’s basically a new table that includes another sort key and gets automatically updated when new data pops
think of it as: a way to define some access pattern on data spread across different partitions
let me give you a decision-tree on what should you opt for👇
Consistency - Strong or Eventual (and the 💸 cost)

will try to be brief, as I provided a logical diagram of when to use what 👆
Eventual Consistency
dynamoDB reads one replica (whichever closest geographically to the user). if the replica is a few ms behind a recent write, you might get ms stale data
latency is sub 5ms 😅 (not that eventual even lol)
cheaper than keeping strong consistency.
fitting for newsfeeds, dashboards, caches, idempotency look-ups..
Strong Consistency
one of the partitions acts as coordinator, who waits until majority of replicas have the latest write. after that, read from one of those replicas.
latency goes down to 1-2ms
much higher cost, almost 2X
finances, inventory counters..
Global tables
Replicates to N regions in < 1 s; 99.999 % SLA (docs.aws.amazon.com, docs.aws.amazon.com)
conflict rule: last-writer-wins (timestamp)
Zoom scaled from 10 M → 300 M daily participants in 2020 by turning on global tables + on-demand mode —> no downtime during the pandemic surge
diagram to share
grab AWS’s official “two-region active-active” graphic (search “global tables how it works”) or HelloInterview’s side-by-side latency map — both render nicely in newsletters.
ship-it checklist
✅ same autoscale settings per region
✅ route writes smartly (single-primary if you hate conflicts)
✅ test fail-over with Route 53 weight-0→100 flip
DynamoDB Streams - CDC meets Lambda
turn on DynamoDB Streams → every put/update/delete appears in a 24 h ordered log, persisted on disk.
wire it to AWS Lambda for instant triggers (webhooks, analytics, Elasticsearch sync)
a very quick way to implement CDC into your design. Very good to use when you need to have complex search queries, and you know a normal DB won’t scale so you’d need ElasticSearch. In that case, simply use Streams from Dynamo X Lambda to put all data into the ElasticSearch for real-time search results!
TTL in Dynamo 😵💫 (set-and-forget data expiry)
Add expiresAt:

DynamoDB removes rows “a few hours” after the timestamp - zero write cost and the deletion shows up in the stream so you can archive to S3.
⚠️ a VERY important note here is: you can’t use Dynamo’s TTL like you would use TTL on a Redis cache for example. Since we are working with the disk here, this data isn’t flushed within ms of this TTL expiring.
the Dynamo sweeper actually removes it minutes to hours after expiring!
so.. when DynamoDB shines??
configurable consistency based on the flow/system needs
simple look-ups - GetItem by ID, paginate “latest 20” lists - always O(1)
spiky / unknown load - on-demand mode absorbs 0 → 500 k QPS without warm-ups
global audience - turn on Global Tables; write in EU, read in US < 1 s later
serverless stack - Lambda & API Gateway need no persistent connections
short-lived data - add a
TTLattribute for rows auto-expiration without the need of a cron job!

if so nice, why not use it everywhere?
although DynamoDB offers almost anything, it’s still a non-relational database & it has it CONs. here’s a list of situations where you wouldn’t use it ⚠️
need on-the-go filtering or JOINs - i.e you don’t have:
WHERE price < 10 AND color='red';you must pre-model queries or do table scan (slow + 💸)big multi-row transactions - ACID exists in Dynamo, but with a 25-item limit.. i.e. complex business logic will be better of with SQL
heavy analytics / aggregations - no
GROUP BY😥.. but you will either way move data to some analytics center, using OLAP optimized DBs and queriesleave a comment if you can think of more? 👇
🗂 ready-made interview one-liners
you can keep this as notes during an interview.. although, if you really read and studied Dynamo, you will most probably do just fine without these 💪
“DynamoDB is basically auto-sharded key-value storage - So I think about keys, not servers.”
“Strong reads cost 2 × RCU; I reserve them for balances - everything else is eventual.”
“Need world-wide speed? Global Tables give same API, just lower latency for remote users.”
“If we outgrow its query model, we can stream changes into Redshift for analytics.”
well, that was it 👏 congrats on reaching the end of the article 🎉
i hope it was valuable and you managed to learn something new from it!
DynamoDB is a remarkable piece of technology and it can come in very handy in system design interview (and real world systems as we’ve seen!)

if you wanna dive even deeper, read the Dynamo paper by Amazon!
that being said, if you wanna see more such blog-articles, subscribe & drop a ❤️ - it really means a lot to me!
Great post! I love the insight “you just need to learn PostgreSQL and DynamoDB. that gets you covered in terms of the DB choice on the interview!”